핵심 : SAE space에서 contrastive하게 feature를 선택해서 steering할 수 있다.
0. Abstract
LLM의 behavior를 효율적이고 믿을 수 있게 통제하는 것은 중요한 과제다. activation steering(hidden state에서 steering vector를 추가)은 좋은 방법 중 하나이지만, 아직까지 정확도와 해석 가능성에 한계가 있다. 따라서 저자들은 Contrastive Activation Addition (CAA)와 SAE-Targeted Steering (SAE-TS)를 바탕으로 Feature Guided Activation Additions (FGAA)라는 방법을 제안한다. SAE의 latent 공간에서 작동하며 원하는 SAE feature를 선택해서 정확하고 해석 가능한 steering vector를 찾아낸다. 해당 연구에서 steering scale과 모델의 성능의 trade-off 또한 설명한다.
1. Introduction
LLM behavior를 바꾸기 위한 여러 시도들이 존재하지만, 기존 방식들은 모두 한계가 존재한다. 파인튜닝은 연산량이 막대하며, 데이터셋을 구축해야 한다는 어려움이 있다. Instruction 바탕의 시도는 adversarial input이나 어려운 task에 대해 robust함이 약하다. 최근에 주목 받고 있는 Activation steering은 해석가능성, 정확도, 일관성 부분에서 아직 한계가 존재하며, output quality가 안좋아진다는 단점이 있다.
최근에 나온 SAE-TS 연구와 CAA를 엮어서 제안하는 FGAA 방식은, 성능과 steering 효과, output 통일성 측면에서 모두 높은 성능을 보임을 확인한다. 추가적으로, steering scale이 달라짐에 따라 모델의 generalization 성능에 어떤 영향을 주는지도 조사한다.
2. Related Work
Mechanistic Interpretability and SAEs
인간이 이해할 수 있는 알고리즘으로 학습시키는 loss가 없음에도, 모델들은 자연스럽게 그런 방식으로 학습한다는 전제로 한다. 기본적으로 뉴런들은 여러개의 특징을 encode하는 polysemancity를 가지는데, Sparse Autoencoder(SAE)로 특징들을 분리해낼 수 있다.
Linear Representation Hypothesis
신경망들이 high-level의 개념을 linear하게 표현한다는 가설이다. SAE를 사용한 특징 추출이나, residual stream에서 특징을 찾는 것, activation steering 방법들의 결과는 해당 가설을 뒷받침한다.
Activation Steering
activation을 조작함으로써 inference 과정에서 LLM의 행동에 영향을 줄 수 있음을 보인다. 특정 행동의 postive 프롬프트와 negative 프롬프트의 residual streamactivation 차이를 구하는 방식(CAA)이나, steering 벡터가 SAE feature들을 얼마나 영향을 주는지 예측하는 선형함수등의 방법들이 존재한다.
3. Feature Guided Activation Additions
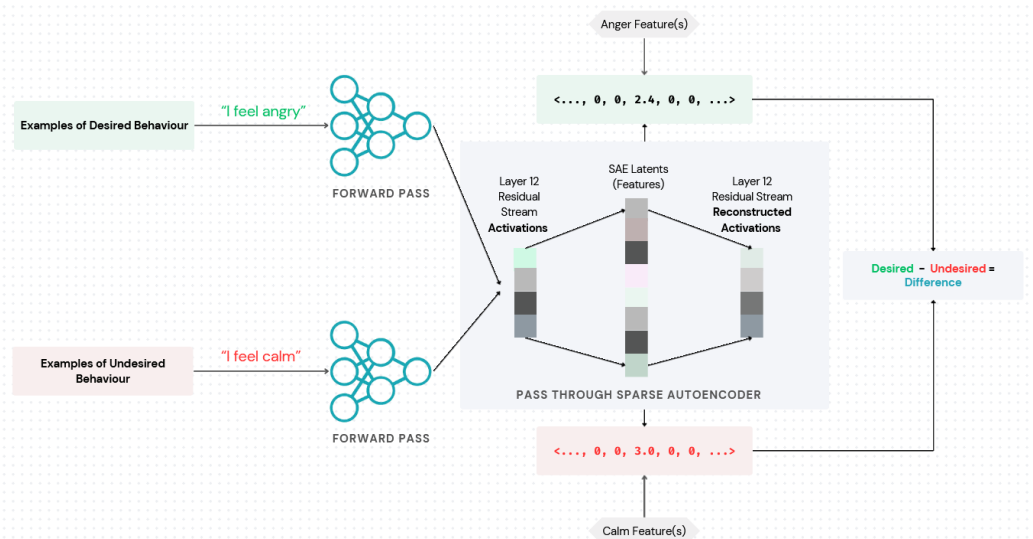
3.1 SAE-Based Contrastive Analysis
CAA는 raw activation 값으로 작동했다면, FGAA는 SAE 공간에서의 contrastive 차이를 사용한다.
3.2 Feature Filtering
3개의 단계를 거쳐서 difference 벡터를 target 벡터로 전환한다.
- Density Filtering: 기준값(0.01)보다 높은 activation을 가지는 feature는 0으로 설정한다. 이는 높은 activation을 가지는 feature는, 여러 input들에 대해서 공통적으로 높게 나오기 때문에 차이가 나는 행동을 특정하기 어렵기 때문이다.
- BOS Feature Removal: BOS 토큰에 가장 강하게 활성화되는 feature 또한 0으로 설정하여 제거한다.
- Top-K Selection: 남은 feature들 중에서 가장 positvie하게 활성화된 feature(n1)와 가장 negative하게 활성화된 feature(n2)를 사용해서 target 벡터를 만든다. 이는 noise에 해당하는 약하게 활성화된 feature들을 제거할 수 있게 한다.
3.3 Linear Approximator Optimization
최적의 steering 벡터를 찾기 위해 linear effect approximator를 선형 함수로 표현하여 steering 효과를 예측한다. 이것을 사용하여 target 벡터를 정규화한 최적의 steering vector를 구한다. 정규화하는 이유는 target 벡터의 크기와 무관하게 scaling을 지원하고 안정적인 steering 효과를 유지하기 위함이다.
3.4 Final Steering Application
최적의 steering vector를 steering scale와 곱한 뒤에, 생성 과정 중 hidden state에 벡터를 적용한다.
4. Evaluations And Discussion
4.1 Effectiveness of FGAA for Steering
연산의 부담과 공개된 weight의 한계로 인해, Gemma-2-2B와 9B 모델의 12번째 layer에서 실험을 진행한다. gpt-4o-mini로 행동적 alignment와 일관성을 평가한다. 평가를 위해 모든 steering 벡터는 L2 정규화를 한 뒤에 적용한다.
기존 steering 방법들(CAA, SAE feature, SAE targeted)의 한계를 극복한다.
- Programmatic Feature Selection: SAE-TS와 SAE 방법들은 steering할 feature를 수동으로 선택해야 한다. 하지만 FGAA는 관련된 feature들을 찾고, feature들 간의 관계를 찾아서 크기를 조절한다. 크기가 작은 SAE에서는 원하는 feature를 정확하게 특정하는게 어려운 만큼, FGAA가 더 빛을 발한다.
- Interpretability: CAA 방식은 불분명한 activation space에서 작동한다면, FGAA는 SAE에서 원하는 효과를 결정한 뒤에 steering vector를 구성한다는 점에서 통제가 쉽고 해석하기가 쉽다.
4.2 Effects of Steering on General Model Capabilities
OpenWebText, MMLU(Massive Multitask Language Understanding), MMLU-Pro 벤치마크에 대해 실험하며, steering이 모델 성능에 어떤 영향을 주는지를 확인한다.
steering scale이 50 이하일 때는 성능이 baseline과 비슷한 수준으로 유지된다. 하지만 50을 넘으면서 성능이 급격하게 내려가서 거의 점수가 0이 된다. 50 이하가 steering 효과를 주면서 모델 성능을 유지하는 기준이며, 그 뒤로는 성능과 steering의 trade-off임을 확인할 수 있다.
CAA, SAE-TS, SAE 방식들은 MMLU-Pro에서 조금의 steering이 성능을 오히려 높이는 효과를 확인할 수 있는데, NEFTune 연구에서 제안한 소량의 노이즈가 성능을 높이는 효과로 볼 수 있다. 반면, FGAA는 초기에 이런 bump가 없기 때문에, steering이 더 정확하게 들어가서 noise가 없다는 것으로 볼 수 있다고 주장한다.
5. Limitations
SAE를 바탕으로 진행했기에, SAE 자체의 정확도에 의해 성능이 많이 제한될 수 있다고 주장한다. 또한, n1과 n2 파라미터를 선택하는건 task에 많이 의존적이었기 때문에 일반화하기가 어렵다는 한계가 존재한다고 이야기한다.
6. Future Work
SAE의 차원 크기와 SAE feature의 품질이 steering 성능에 어떤 영향을 주는지를 확인하는 연구 방향이 존재한다. 또한 높은 steering scale에서 모델 성능의 저하를 줄이는 방법에 대해서도 연구가 가능하다.
RLHF 모델에서 sycophancy, hallucination, refusal와 같은 safety task에서 fGAA를 적용하는 것에 대한 연구 방향도 유효하다고 주장한다.
7. Conclusion
CAA와 SAE 활용 steering을 결합한 FGAA 방식을 제않나다. 여러 task에 대해 기존 steering 방법들보다 더 나은 성능을 보여주는 것을 확인한다. 일반적인 activation steering에서 steering scale과 모델의 기본 성능과의 trade-off 관계 또한 보여준다.
논문 출처 (ICLR Workshop Building Trust 2025):
https://arxiv.org/abs/2501.09929