핵심 : Backtracking하는 과정을 학습시켜 LLM의 성능을 높인다.
0. Abstract
slow-thinking mechanism을 LLM에 적용하는 방법은 Level 2 AGI Reasoner에 한층 가깝게 한다. 하지만 overthinking과 외부 모델의 과의존하는 문제가 존재한다. 이를 해결하기 위해서는 탐색하는 과정을 내재화해야 되고, 이는 backtracking을 통해 가능해진다고 해당 논문은 주장한다. self-backtracking을 통해 LLM이 train과정과 inference 과정에서 backtracking할 수 있도록 한다. slow-thinking을 fast-thinking으로 내재화하여 추론 능력이 크게 향상되는 것뿐만이 아니라 효율성도 높일 수 있었다.
1. Introduction
slow-thinking mechanism(대표적인 예시: OpenAI의 o1, o3 모델)이나 self-reflection, self-correction등의 테크닉으로 성능을 향상시키는 시도들이 있다. 하지만 진정한 Reasoner를 위한 방법으로는 부족한데, overthinking의 문제와 외부 모델에 대해 의존성이 높다는 문제가 있기 때문이다.
결국 모든 문제는 탐색하는 과정을 내재화하지 못했다는 것에서부터 출발한다. 단순히 외부모델을 활용하는 것은 어려운 문제에서는 성능을 제한시키고, 쉬운 문제에서는 overthinking을 하게 만든다. 많은 탐색 알고리즘의 핵심인 백트래킹을 LLM에 내재화할 수 있다면 해결할 수 있다고 주장한다.
따라서 해당 논문은 Self-Backtracking을 제안한다. 현재의 상태가 최적의 아닌 상태임을 파악하고 이전 상태로 돌아가게 하는 능력을 학습하여, test 과정에서는 dynamic하게 탐색을 한다. 이 방식을 통해 1) 불필요한 백트래킹이 일어나지 않아 overthinking이 줄어들고, 2) 외부 모델에 의존하지 않아도 된다.
2. Related Work
Learn from Search Trajectories : Monte Carlo Tree Search (MCTS), BFS, A* 알고리즘등의 다양한 탐색 전략들을 활용한 연구들이 존재한다.
Learn from Mistakes : 많은 연구들이 LM이 자신의 실수를 인식하고 수정할 수 있는지 확인한다. 기존 데이터들을 사용해서 현재 상태에 에러가 있는지 확인하고, 재생성하는 시도들도 존재한다. 해당 논문에서는 이러한 인식 능력을 내재화함을 보여준다.
Inference Strategies of LLM Reasoning : greedy decoding, beam search, majority voting과 같은 시도들도 존재하였고, Best-of-N과 같은 알고리즘도 활용되었다. Outcome Reward Model(ORM), Process Reward Model(PRM)과 같은 방식도 있는데, 외부 모델 사용으로 인한 연산 비용이 증가한다는 문제가 있다.
3. Preliminary
3.1 Problem Setup
reasoning 문제를 Stream of Search 연구에서 정의했듯이 Markov Decision Process (MDP)로 모델링한다. 각 state에서 action을 통해 다음 state로 진행되며, 각 state에는 그에 대응하는 reward가 존재한다. solution은 trajectory로 표현된다 (= state와 action의 연속)
3.2 Backtracking
state과 action으로 reasoning 문제를 정의하면, 자연스럽게 tree 구조를 사용할 수 있다. 해당 논문은 tree에서 solution을 탐색하기 위해서 주로 사용되는 Backtracking을 LLM이 학습하도록 하는 것에 집중한다. Backtracking 능력을 내재화하여 외부 도구나 모델에 의존하지 않을 수 있도록 한다.
4. Self-Backtracing in Language Models
Self-Backtracking에 대해서 크게 3가지 부분으로 나누어서 설명한다:
- training 과정 : 특정한 최적화 목표와 포맷에 맞는 데이터셋을 구성한다.
- inference 과정 : 외부 도구 사용 없이 백트래킹 능력을 통한 효율적인 탐색 알고리즘을 사용한다.
- self-improvement 과정 : 탐색 결과를 다시 모델에 넣어줌으로써 slow-thinking에 해당하던 것을 fast-thinking을 넣는다.
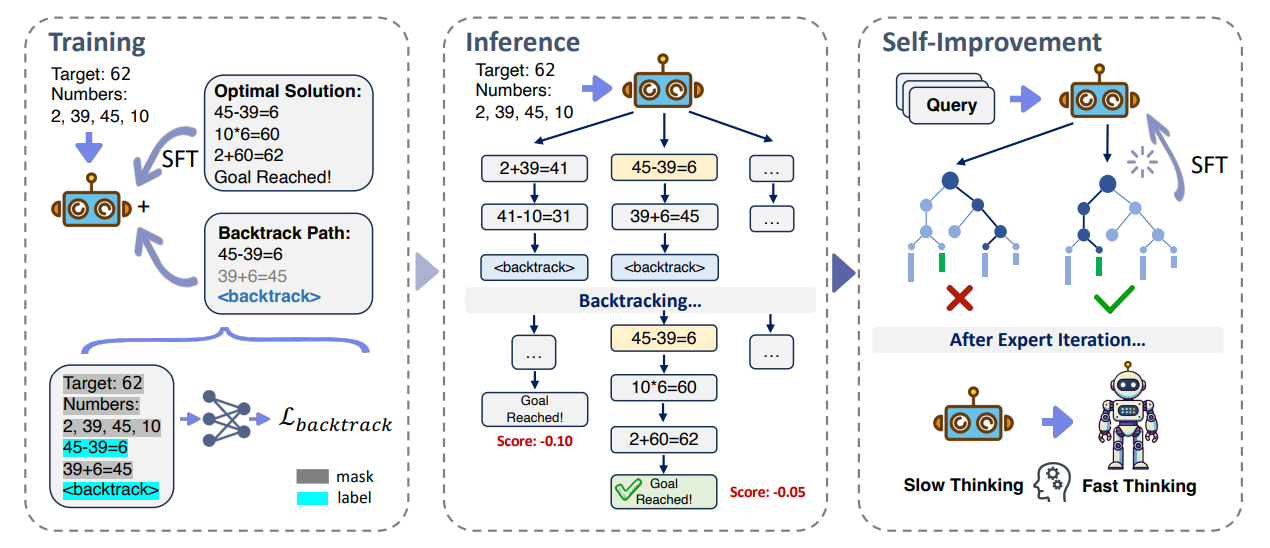
4.1 Learn to Backtrack
가장 최적의 solution에서 일부를 잘라온 다음에, 일부러 error가 있는 action을 concat하고 <backtrack> 토큰을 넣어서 백트래킹 데이터셋을 구성한다. 이를 통해 모델은 언제 백트래킹해야 할지 학습한다. 한번의 백트래킹만 학습시켜도 재귀적 특성 때문에 multiple-step에 걸쳐서 백트래킹을 할 수 있다.
Loss의 경우, optimal solution을 찾아갈 수 있게 하고, <backtrack> 토큰을 예측하도록 하게 설정한다. error를 예측하는 loss는 생략되어 있는데, 모델의 목표는 이처럼 errorneous한 action을 잘 예측하는 것이 아니라 잘못된 reasoning path로 안빠지는 것이기 때문이다.
4.2 Inference with Backtracking
백트래킹을 해야 되는 when과 where을 학습했기 때문에 inference 과정에도 활용할 수 있다. 이 과정으 크게 3가지 단계로 나눌 수 있다.
① Expansion : N개의 예측을 하면서 <backtrack> 토큰이 있는 것과 없는 것을 나눈다. 토큰이 없는 예측들은 바로 candidate set에 들어간다.
② Backtracking : route(n)개의 예측들을 골라서 한 개의 step 전으로 돌아가서 다시 확장한다.
③ Selection : negative perplexity를 기준으로 하여 가장 높은 점수의 reasoning path를 선택한다.
4.3 Self-Improvement
slow thinking 능력을 fast thinking으로 전달하기 위해서, slow thinking으로 데이터들을 생성한다. 그 다음에는 정확한 데이터들을 선별해서 SFT(Supervised FineTuning)으로 fast thinking 모델을 학습시킨다.
5. Experiments
5.1 Experimental Setup
데이터셋으로는 Countdown task를 사용한다. training set은 최적의 solution과 backtracking 데이터들로 구성되어 있다. test set은 1) 기존의 target에 대한 새로운 조합과 2) 아예 새로운 target으로 구성되어 있다.
backtracking 데이터는 error 유형에 따라 3가지로 나눌 수 있다. 해당 error 다음에는 <backtrack> 토큰을 붙인다.
① Exploration Errors : DFS로 탐색을 하다가, 올바른 solution이 아니라면 해당 step을 종료한다.
② Computational Errors : 계산을 실수한 경우이다.
③ Rule Violations : 규칙에 따라 가능하지 않은 연산자를 사용한 경우이다.
5.2 Main Results
b=backtracking 가능 횟수, N = reasoning path 개수
Self-Backtracking을 했을 때, Reasoning 능력이 크게 향상되고 Self-Improve도 가능하다는 것을 보여준다. slow-thinking의 능력이 fast-thinking 모델로 전달이 되는 것도 확인할 수 있다.
5.3 Analysis
- backtracking의 유무는 dramatic한 차이가 있으나, backtracking이 가능한 횟수를 늘린다고 해서 큰 성능 향상은 보이지 않음.
- N을 늘릴수록 “Not reached target” 유형의 에러는 줄어드나, 타겟 값에 맞추기 위해서 최종 step에서 끼워맞추다가 연산 실수를 하는 비율이 늘어남.
6. Conclusion
탐색 과정과 언제 어디에서 백트래킹을 못하고 있는 추론 모델들의 문제를 해결하기 위해 Self-Backtracking 기법을 제안한다. overthinking의 문제도 해결하면서, 외부 도구들에 의존하지 않을 수 있게 한다.
Limitations and future work : general한 reasoning task들에 대해서 확인하지 못했으며, scale up이 필요하다.
논문 링크:
https://arxiv.org/abs/2502.04404

